CELPIP-IELTS Concordance
Comparing CELPIP and IELTS Scores
This report describes the concordance exercise conducted for CELPIP – General and IELTS General Training.
The report presents IELTS-CELPIP concordance tables for each test section (Reading, Listening, Speaking, Writing) and an overall table for which an equipercentile equating procedure was employed. All statistical analyses were conducted using RStudio software. The report begins with test descriptions, includes methodology for the study, outlines the concordant results followed by references and an appendix providing candidate survey / exam familiarity data.
In terms of the results interpretation, we caution against the use of concordance tables in isolation, without a construct comparison of tests and an easily accessible summary of their differences, and what scores mean on each test.
Overall Score Comparison Chart:
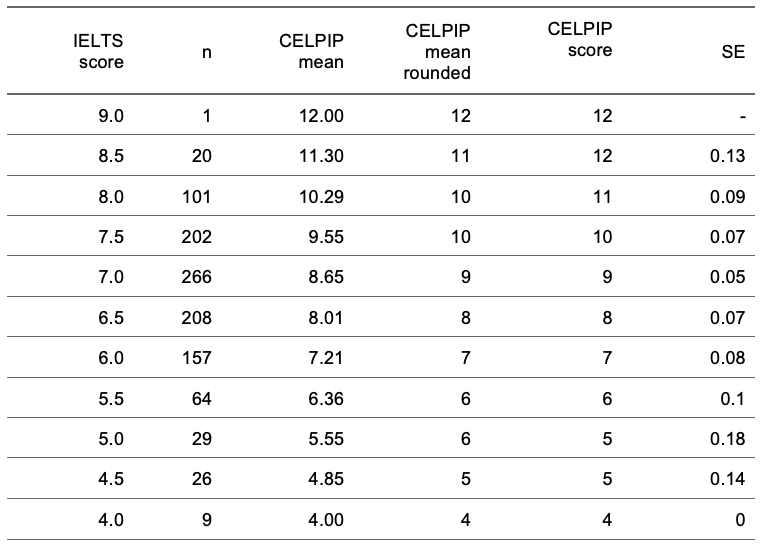 Specific Section Comparison Charts:
Specific Section Comparison Charts:
CELPIP IELTS Reading Section
- CELPIP IELTS Reading Section Comparison Chart
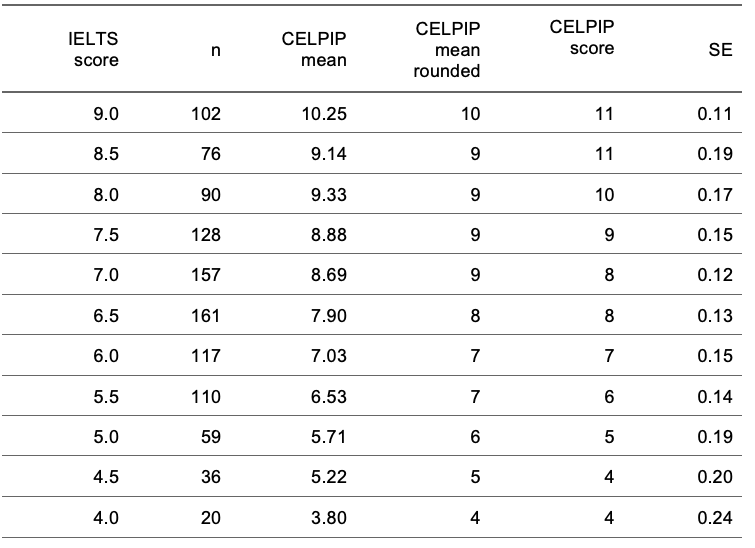
CELPIP IELTS Listening Section
- CELPIP IELTS Listening Section Comparison Chart
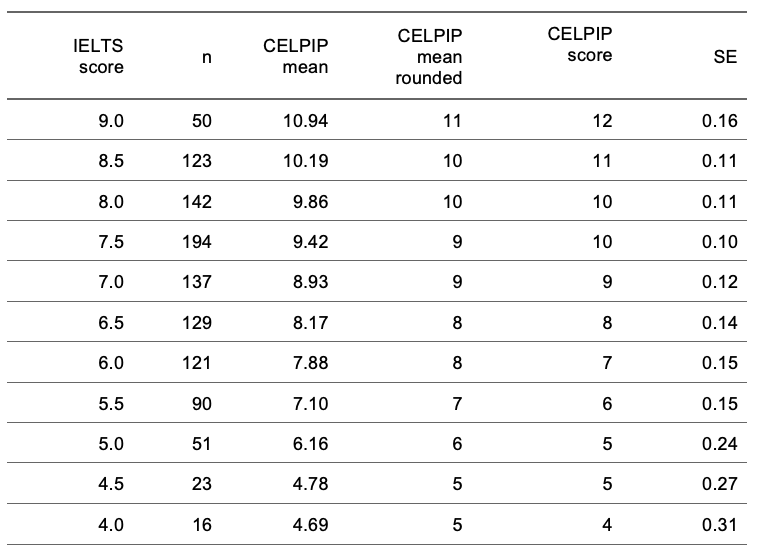
CELPIP IELTS Writing Section
- CELPIP IELTS Writing Section Comparison Chart
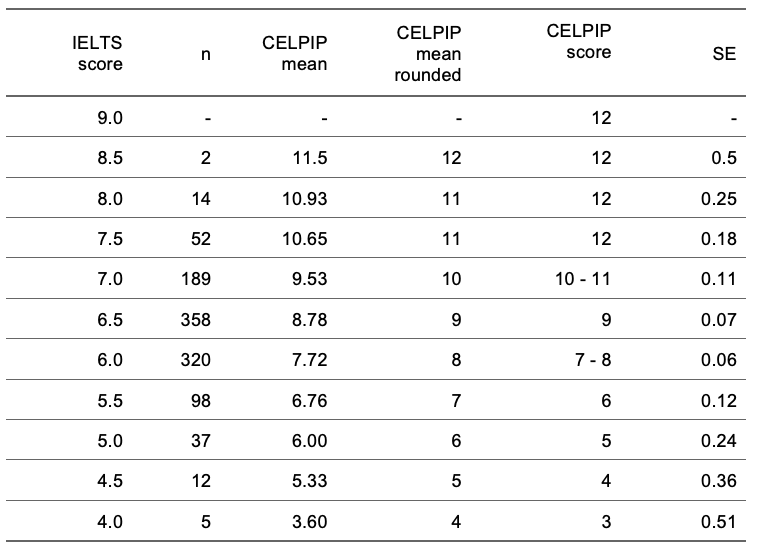
CELPIP IELTS Speaking Section
- CELPIP IELTS Speaking Section Comparison Chart
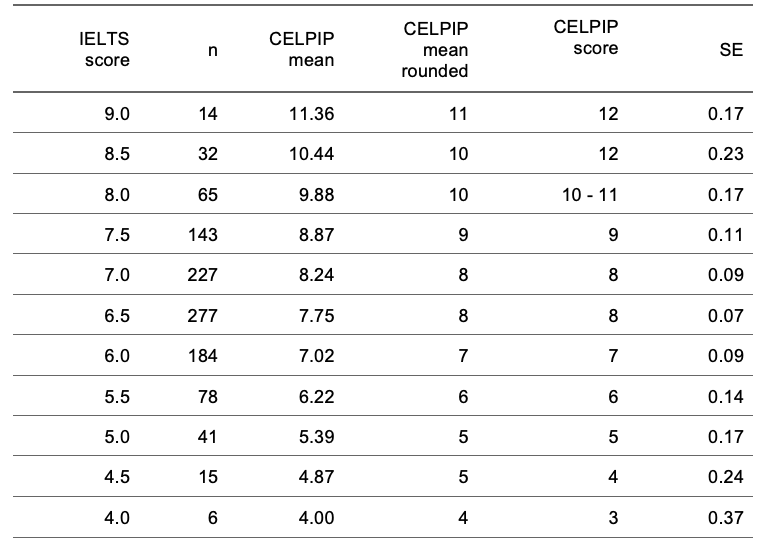
Conclusion and Limitations
This report has described our collective research efforts to design and implement a robust concordance study. When interpreting specific score levels in concordance studies, several important considerations must be taken into consideration to ensure accurate and fair use of the results. First, the accuracy of score conversions may vary, especially at the extremes of the score range.
Concordance at intermediate score levels (i.e., mid-range proficiency) tends to be more reliable due to the availability of more data and consistent measurement. In contrast, extreme scores, whether very high or very low, are often based on fewer observations, leading to potential variability in the accuracy of linkages. In this study, the observed ranges for IELTS Speaking and Overall scores were somewhat limited. While it would have been desirable to include candidates with scores below IELTS 3.5, the practical challenges of obtaining such candidates were considerable due to the natural distribution of scores within the population.
Moreover, the design and content of tests influence score levels and concordance. Although IELTS and CELPIP share similarities in item types and construct, differences in format, scoring scales, and their emphasis on specific skills lead to discrepancies in score alignment. Scores from one test do not directly map to scores from another, even when both tests aim to measure related constructs.